😃 Greetings!
I have joined Alibaba DAMO Academy as a research scientist via the Alibaba Star (‘阿里星’) top talent program, working on cutting-edge problems in foundation models. I also hold a research position at Zhejiang University, working with Prof. Yi Yang. I obtained my PhD from Zhejiang University in the beautiful summer of 2024 (from Sept. 2019), under the supervision of Prof. Dong Ni, Prof. Samuel Albanie (University of Cambridge/DeepMind), Deli Zhao (Alibaba DAMO) and Shiwei Zhang (Alibaba Tongyi Wan Team). I have undertaken a visiting Ph.D. program at MMLab@NTU, supervised by Prof. Ziwei Liu and Dr. Chenyang Si.
My representative projects include VGen (includes InstructVideo), VideoComposer, the Lumos series (includes Lumos-1, UniLumos, LumosX and Lumos-Nexus), the RLIP series (v1 and v2), the DreamVideo series (v1 and v2) and ModelScopeT2V.
I am currently interested in Video World Models, Multimodal Large Language Models and Video Unified Models.
My ultimate goal is to achieve interactive intelligence to shed light on human well-being.
I lead a small research team to work on these topics. Feel free to contact me if you need research instructions.
Generally, my current research interests include:
- 1️⃣ 🌟 Generative models: video world models, visual generation, visual autoregressive models, and visual generation alignment;
- 2️⃣ 🌟 Representation learning: Multimodal LLMs, video understanding, visual relation detection (HOI detection/scene graph generation);
- 3️⃣ AI for science and engineering.
📧 I am recruiting interns to work on cutting-edge problems in foundation models, so feel free to drop me an email at hj.yuan@zju.edu.cn if you are interested in collaborating with me as a full-time researcher/intern or remotely. You can refer to this Job Description (it might be outdated though).
🔥 News
-
2026-06 : 📑 Lumos-Nexus is accepted to ECCV 2026 and FAR is accepted to TMLR.
-
2026-04 : 📑 MathFlow is accepted to ACL 2026 main Oral and FSAR-LLaVA is accepted to IJCV.
-
2026-03 : 🪄🦉 I will serve as an Area Chair for NeurIPS 2026.
-
2026-02 : 📑 DC-SFT, C-Flat++ and CineNeuron are accepted to CVPR 2026.
-
2026-01 : 📑 Lumos-1, LumosX, ProMoE and CogFlow are accepted to ICLR 2026.
-
2025-11 : 📑 UniLumos and VideoMAR are accepted to NeurIPS 2025. Media coverage: 机器之心. Learn to use it from Benji’s AI Playground. Keep going, guys!
-
2025-09 : 🔥 MM-RoPE in Lumos-1 is super useful, and similar ideas have been used in Qwen3-VL. Explanation: Link
-
2025-09 : 👑 I am awarded Zhejiang Provincial Special Grant for Postdoctoral Research (Top 10 in Zhejiang Province).
-
2025-08 : 🪄🦉 I will serve as an Area Chair for ICLR 2026.
-
2025-07 : 🏡 We release Lumos-1, a foundation for autoregresive video generation. Media coverage: [CVer][DAMO矩阵][AI生成未来][PaperWeekly]
-
2025-06 : 📑 SAMora, DreamRelation and FreeScale are accepted to ICCV 2025. Well done, guys!
-
2025-03 : 📑 Dual-Arch and ZeroFlow are accepted to ICML 2025.
-
2024-12 : 📑 FreeMask and AeroGTO are accepted to AAAI 2025. Congrats to Lingling and Pengwei.
-
2024-09 : 📑 EvolveDirector and C-Flat are accepted to NeurIPS 2024. Congrats to Rui and Tao.
-
2024-05 : 📑 PAPM is accepted to ICML 2024 and ArchCraft is accepted to IJCAI 2024. I am happy to see that Pengwei and Aojun are able to publish their work at top-tier conferences.
-
2024-02 : 📑 InstructVideo, DreamVideo and TF-T2V are accepted to CVPR 2024. Thrilled to collaborate with them on these promising projects.
-
2024-01 : 👑 I am honored to receive the Outstanding Research Intern Award (20 in 1000+ candidates) for my contribution in video generation to Alibaba.
-
2024-01 : 📑 LUM-ViT is accepted to ICLR 2024. Congrats to Lingfeng Liu!
-
2023-09 : 📑 VideoComposer is accepted to NeurIPS 2023. Thrilled to collaborate with them on this project.
-
2023-08 : 📑 RLIPv2 is accepted to ICCV 2023. Code and models are publicly available here!
-
2023-08 : 🏡 We release ModelscopeT2V (the default T2V in Diffusers) and VideoComposer, two foundations for video generation.
-
2022-09 : 📑 RLIP: Relational Language-Image Pre-training is accepted to NeurIPS 2022 as a Spotlight/Oral paper (Top 5%). It’s my honor to work with Samuel and Jianwen. Btw, the pronunciation of RLIP is /’ɑ:lɪp/.
-
2022-05 : 📑 Elastic Response Distillation is accepted to CVPR 2022. A great pleasure to work with Tao Feng and Mang Wang.
-
2022-02 : 👑 I am awarded AAAI-22 Scholarship. Acknowledgement to AAAI!
-
2021-12 : 📑 Object-guided Cross-modal Calibration Network is accepted to AAAI 2022. A great pleasure to work with Mang Wang.
-
2021-07 : 📑 Spatio-Temporal Dynamic Inference Network is accepted to ICCV 2021.
-
2021-03 : 👷 I start my internship at Alibaba DAMO Academy.
-
2020-12 : 📑 Learning Visual Context (for Group Activity recognition) is accepted to AAAI 2021.
📝 Publications
A full publication list is available on my google scholar page. The following list is usually outdated.
(*: equal contribution; †: corresponding authors.)
Unified Models (Autoregressive Models)
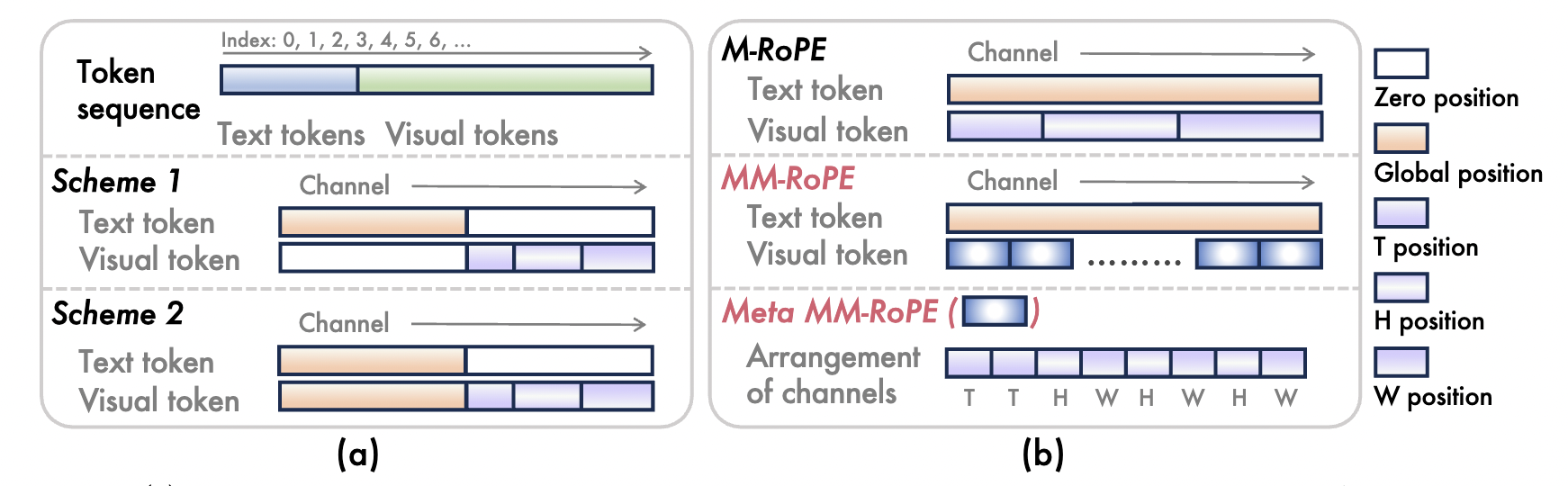
[ICLR 2026] Lumos-1: On Autoregressive Video Generation from a Unified Model Perspective
Hangjie Yuan, Weihua Chen, Jun Cen, Hu Yu, Jingyun Liang, Shuning Chang, Zhihui Lin, Tao Feng, Pengwei Liu, Jiazheng Xing, Hao Luo, Jiasheng Tang, Fan Wang, Yi Yang.


- We introduce Lumos-1, an LLM-based unified model for AR video generation with MM-RoPE (to provide comprehensive frequency spectra) and Autoregressive Discrete Diffusion Forcing (to ensure effective training on and inferring videos).
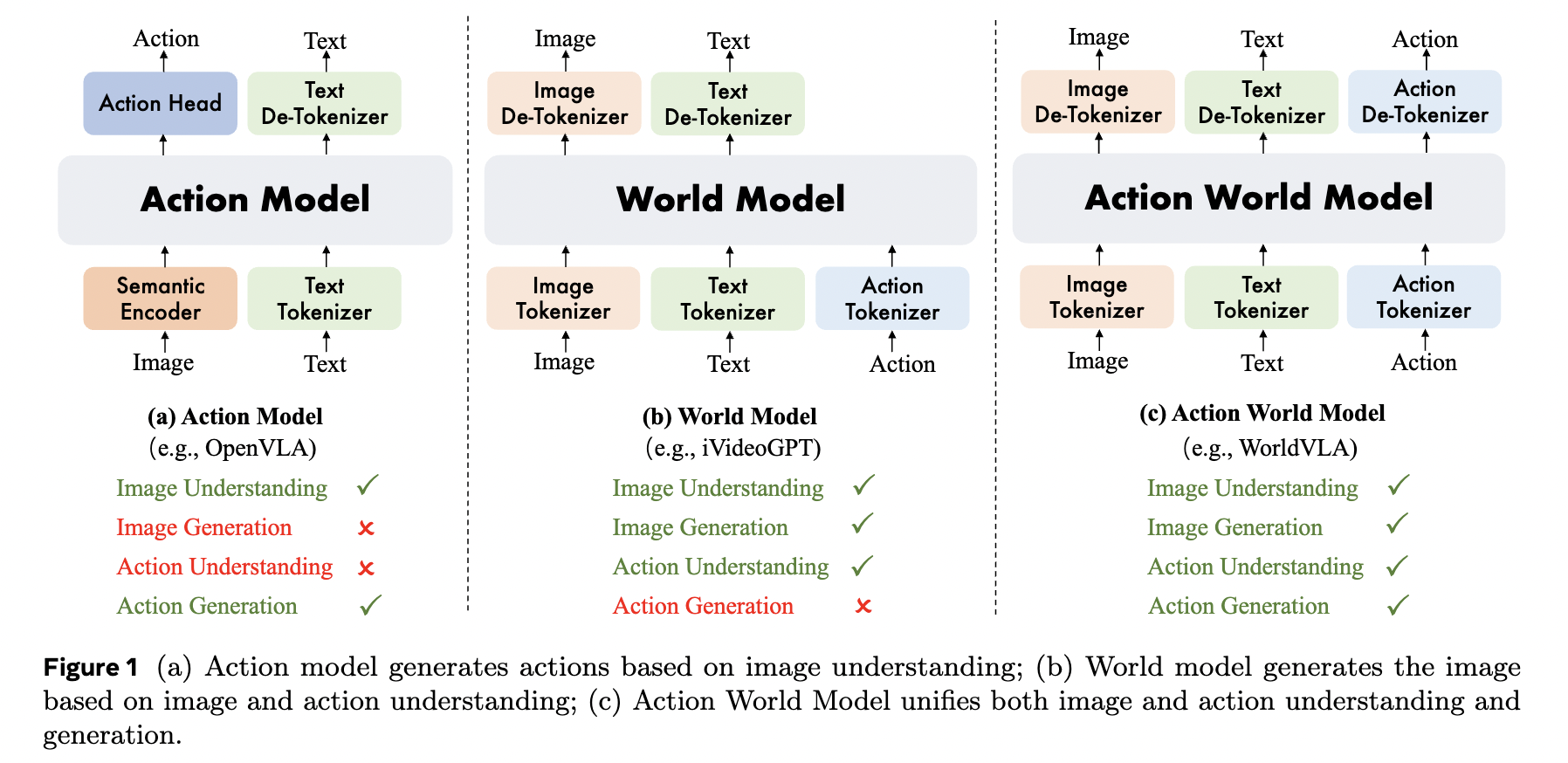
[arXiv] WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, Hao Chen.


- We introduce Lumos-1, an LLM-based unified model for AR video generation with MM-RoPE (to provide comprehensive frequency spectra) and Autoregressive Discrete Diffusion Forcing (to ensure effective training on and inferring videos).
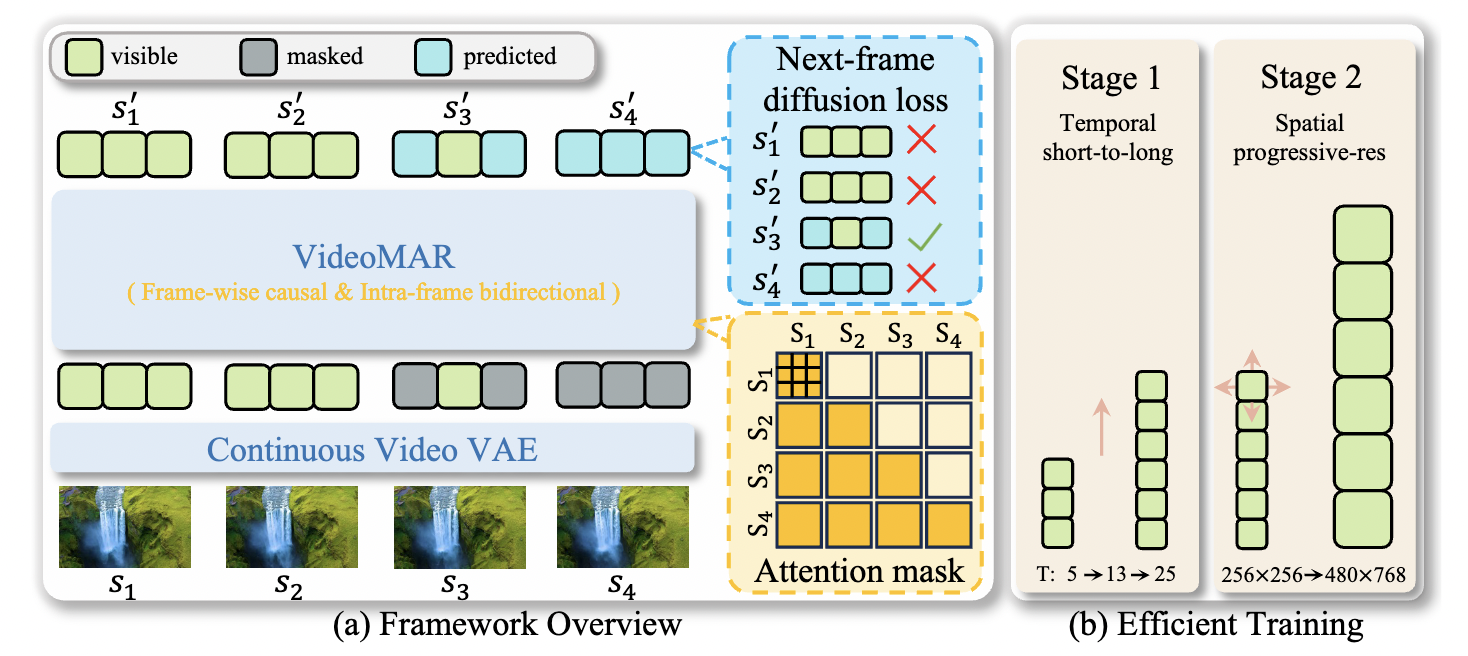
[NeurIPS 2025] VideoMAR: Autoregressive Video Generation with Continuous Tokens
Hu Yu, Biao Gong, Hangjie Yuan, DanDan Zheng, Weilong Chai, Jingdong Chen, Kecheng Zheng, Feng Zhao.
- We propose VideoMAR, a concise and efficient decoder-only autoregressive image-to-video model with continuous tokens, composing temporal frame-by-frame and spatial masked generation.
[arXiv] Frequency Autoregressive Image Generation with Continuous Tokens, Hu Yu, Hao Luo, Hangjie Yuan, Yu Rong, Feng Zhao.
Visual Generation Alignment and its Application
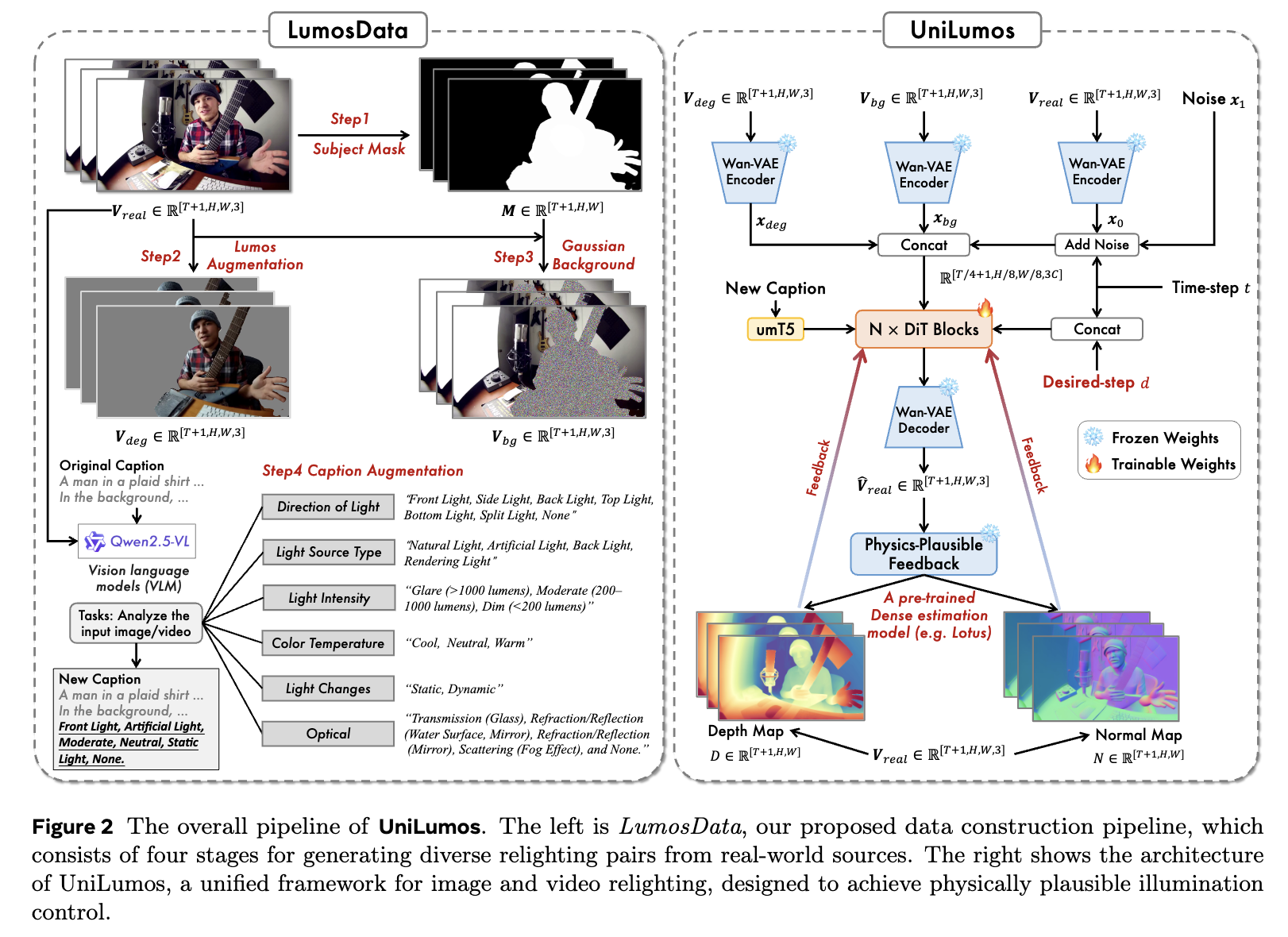
[NeurIPS 2025] UniLumos: Fast and Unified Image and Video Relighting with Physics-Plausible Feedback
Pelen Liu*, Hangjie Yuan*†, Bo Dong, Jiazheng Xing, Jinwang Wang, Rui Zhao, Yan Xing, Weihua Chen, Fan Wang.


- For models, we propose UniLumos, a unified relighting framework for both images and videos that brings RGB-space geometry feedback into a flow-matching backbone.
- For evaluation, we propose LumosBench, a disentangled attribute-level benchmark that evaluates lighting controllability via large vision-language models, enabling automatic and interpretable assessment of relighting precision across individual dimensions.
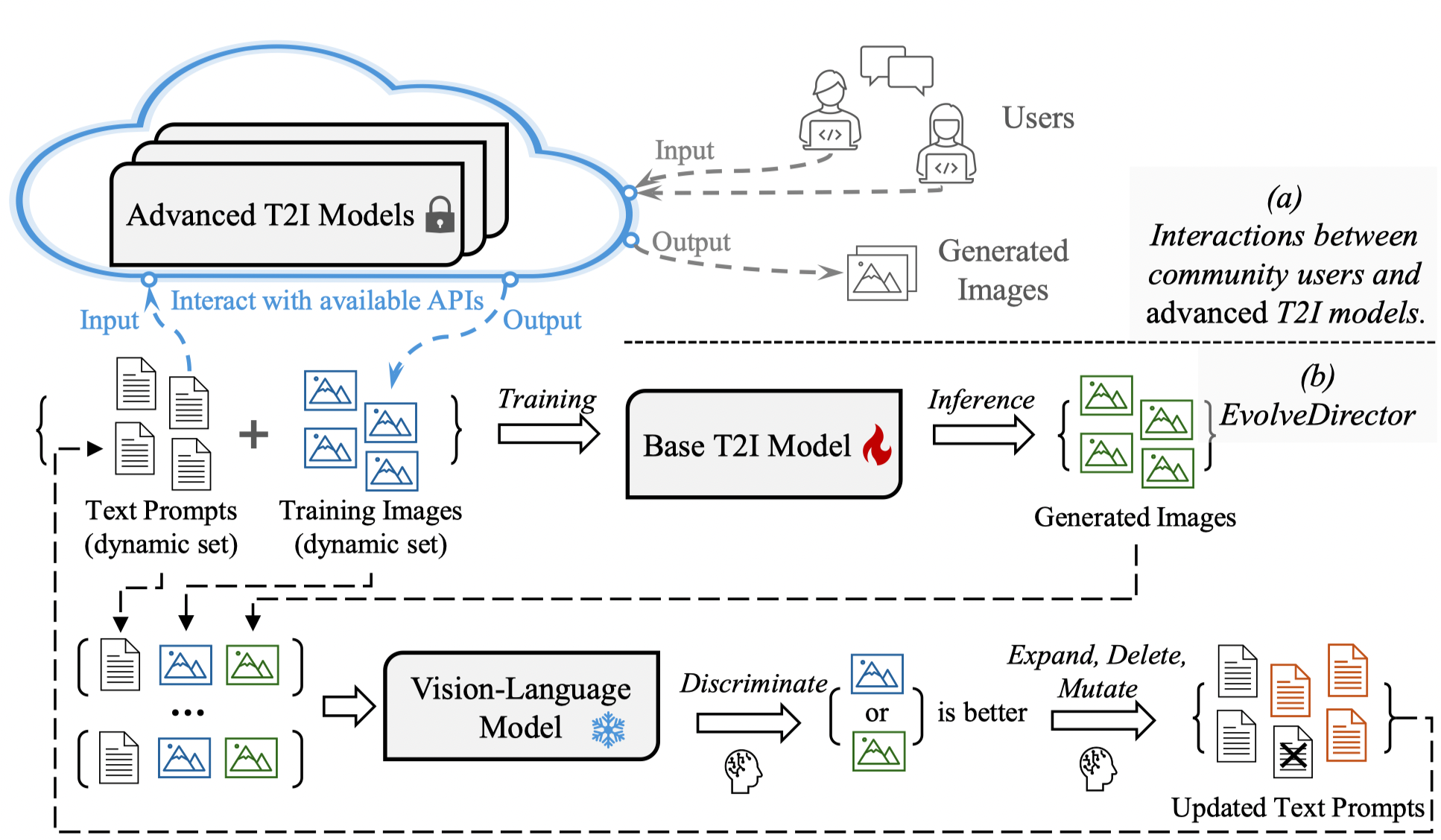
[NeurIPS 2024] EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Rui Zhao, Hangjie Yuan, Yujie Wei, Shiwei Zhang, Yuchao Gu, Lingmin Ran, Xiang Wang, Zhangjie Wu, Junhao Zhang, Yingya Zhang, Mike Zheng Shou.


- EvolveDirector leverages large vision-language models (VLMs) to evaluate visual generation results, guiding the evolution of a T2I model by dynamically refining the training dataset through selection and mutation.
- The trained T2I model, Edgen, powered by EvolveDirector, achieves SOTA performance using only 1% of the data typically required by other models.

[CVPR 2024] InstructVideo: Instructing Video Diffusion Models with Human Feedback
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Yujie Wei, Tao Feng, Yining Pan, Yingya Zhang, Ziwei Liu, Samuel Albanie, Dong Ni.


- InstructVideo is the first research attempt that instructs video diffusion models with human feedback.
- InstructVideo significantly enhances the visual quality of generated videos without compromising generalization capabilities, with merely 0.1% of the parameters being fine-tuned.
Visual Generation / Editing

[ICCV 2025] FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, Ziwei Liu.


- FreeScale introduces a groundbreaking tuning-free inference paradigm that enables high-resolution visual generation by seamlessly fusing information from multiple receptive scales.
- FreeScale unlocks the potential for generating 8k-resolution images and videos, setting a new benchmark in the field.
[AAAI 2025] FreeMask: Rethinking the Importance of Attention Masks for Zero-shot Video Editing
Lingling Cai, Kang Zhao, Hangjie Yuan, Yingya Zhang, Shiwei Zhang, Kejie Huang.
[Project page] [code]
- FreeMask uncovers a critical factor overlooked in previous video editing research: cross-attention masks are not consistently clear but vary with model structure and denoising timestep.
- We quantify this variability and propose FreeMask to select optimal masks for various video editing tasks.
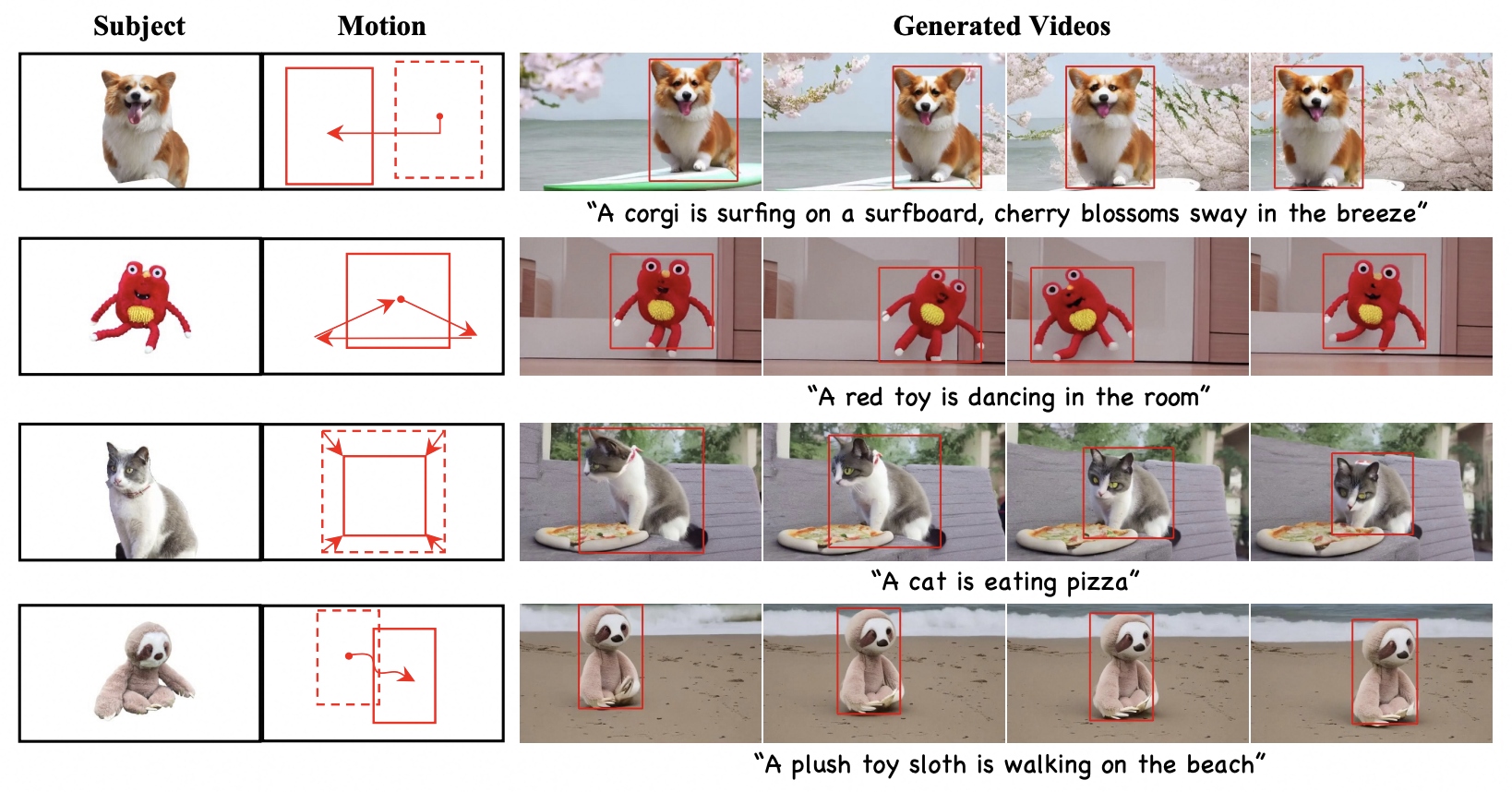
[arXiv] DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Xiang Wang, Haonan Qiu, Rui Zhao, et al.
[Project page] [code] (to be updated)
- DreamVideo-2 is the first zero-shot video customization framework capable of generating videos adhering to a specific subject and motion trajectory.

[CVPR 2024] DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhiheng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, Hongming Shan.
- DreamVideo is the first method that generates personalized videos from a few static images of the desired subject and a few videos of target motion.

[arXiv] I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Shiwei Zhang*, Jiayu Wang*, Yingya Zhang*, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, Jingren Zhou.
- I2VGen-XL is the first publicly available foundation model for image-to-video generation.
- I2VGen-XL decouples high-resolution image-to-video synthesis into two stages: 1) the base stage that generates low-resolution semantically coherent videos, and 2) the refinement stage that enhances the video’s details and improves the resolution to 1280×720.
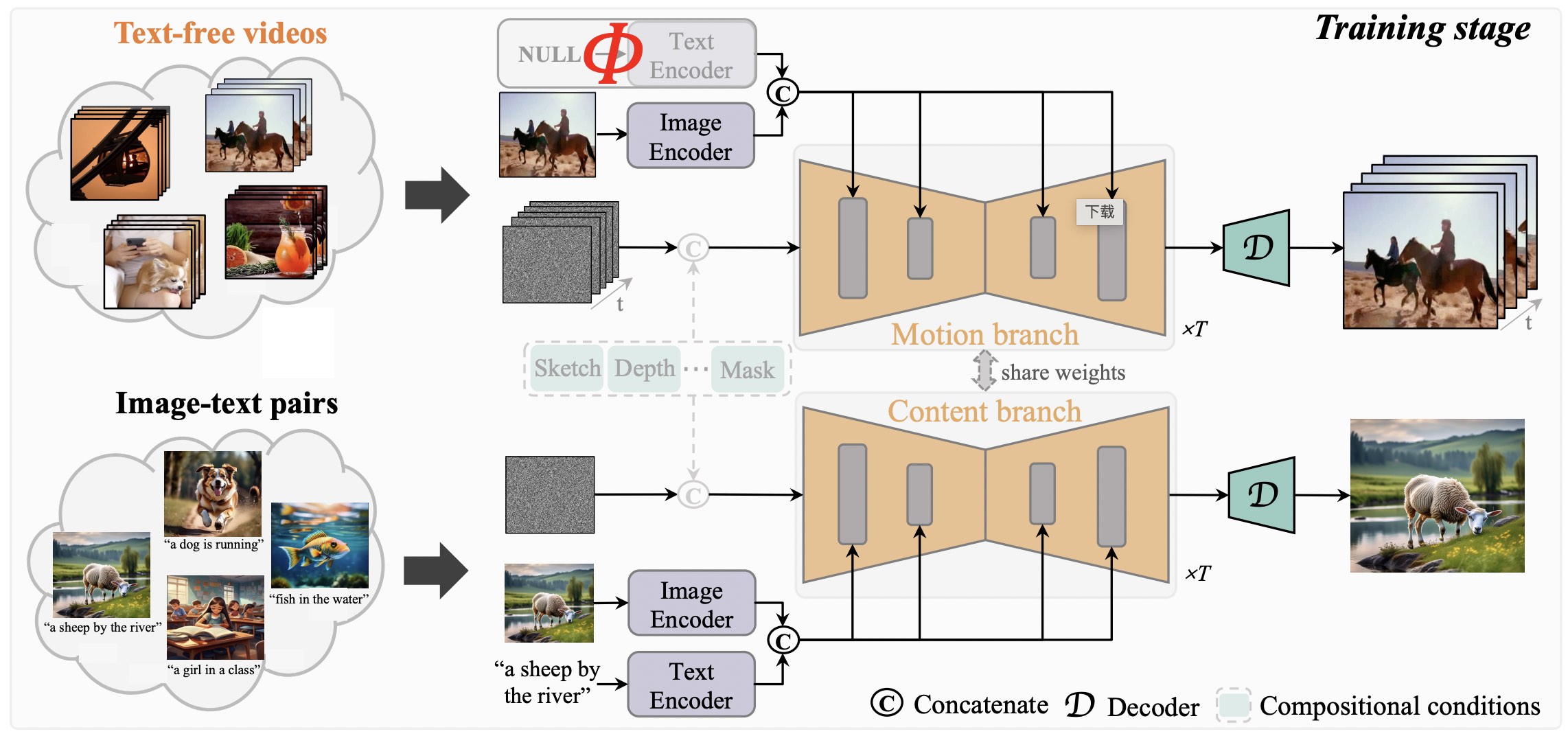
[CVPR 2024] A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
Xiang Wang, Shiwei Zhang, Hangjie Yuan, Zhiwu Qing, Biao Gong, Yingya Zhang, Yujun Shen, Changxin Gao, Nong Sang.
- TF-T2V proposes to separate the process of text decoding from that of temporal modeling during pre-training.
- TF-T2V is proven effective for both text-to-video generation and compositional video synthesis.
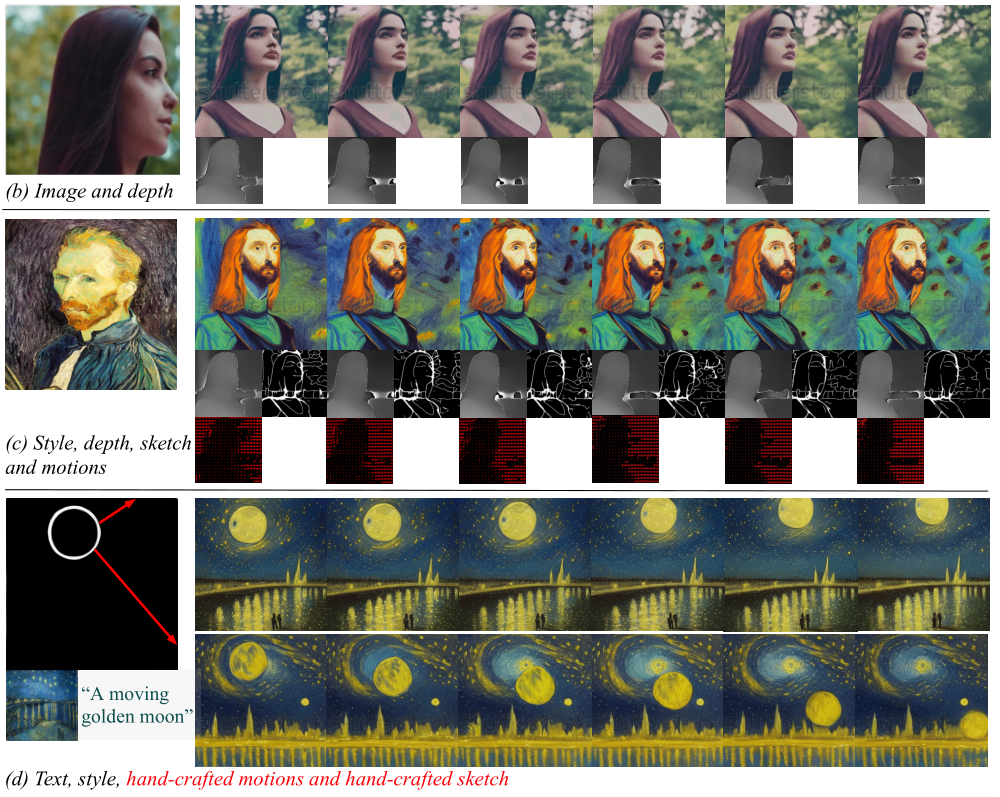
[NeurIPS 2023] VideoComposer: Compositional Video Synthesis with Motion Controllability
Xiang Wang*, Hangjie Yuan*, Shiwei Zhang*, Dayou Chen*, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, Jingren Zhou.


- VideoComposer pioneers controllable video synthesis, seamlessly integrating textual, spatial, and crucially, temporal conditions, through a unified interface for information injection.
- VideoComposer can craft videos using various input control signals, from intricate hand-drawn sketches to defined motions.

[Technical report] ModelScope Text-to-Video Technical Report
Jiuniu Wang*, Hangjie Yuan*, Dayou Chen*, Yingya Zhang*, Xiang Wang, Shiwei Zhang.
[Diffusers]
 [ModelScope]
[ModelScope]

- ModelScopeT2V is the first publicly-available diffusion-based text-to-video model at scale, which has been used by millions of people.
- ModelScopeT2V is selected for inclusion in Diffusers.
Visual Relation Detection (HOI Detection / Scene Graph Generation)
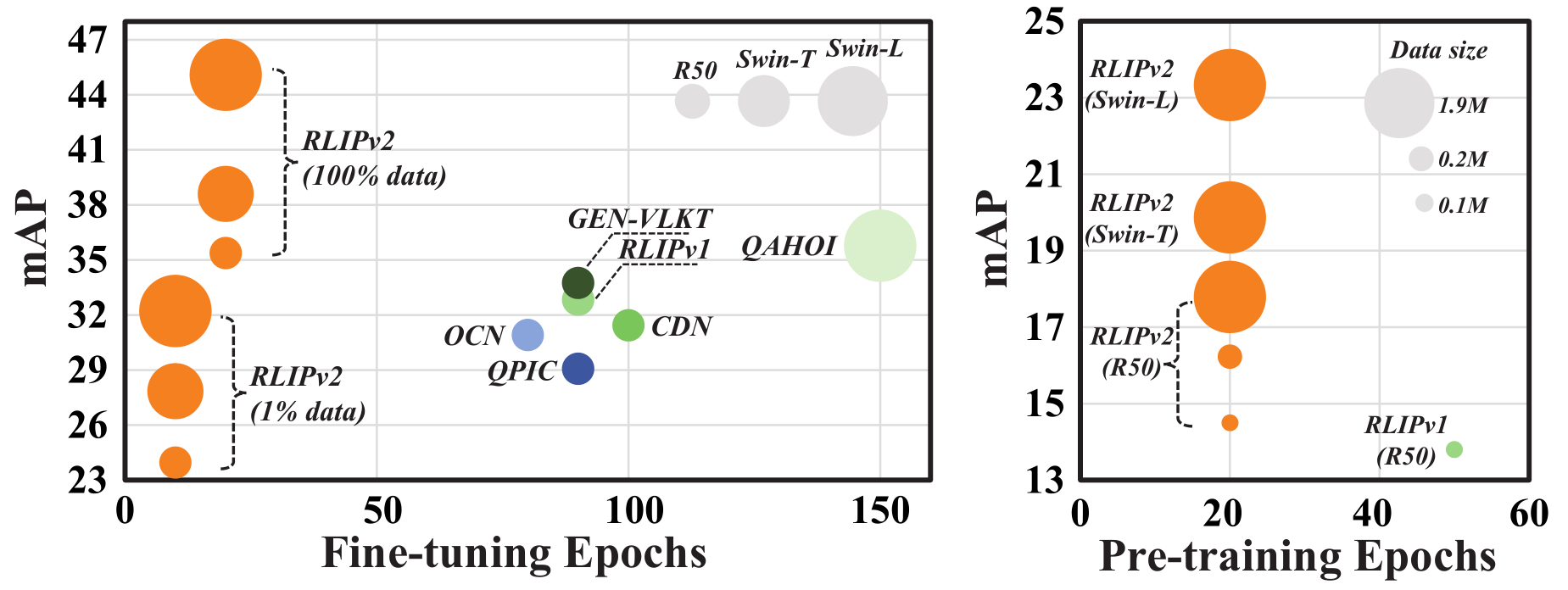
[ICCV 2023] RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Samuel Albanie, Yining Pan, Tao Feng, Jianwen Jiang, Dong Ni, Yingya Zhang, Deli Zhao.


- RLIPv2 elevates RLIP by leveraging a new language-image fusion mechanism, designed for expansive data scales.
- The most advanced pre-trained RLIPv2 (Swin-L) matches the performance of RLIPv1 (R50) while utilizing a mere 1% of the data.
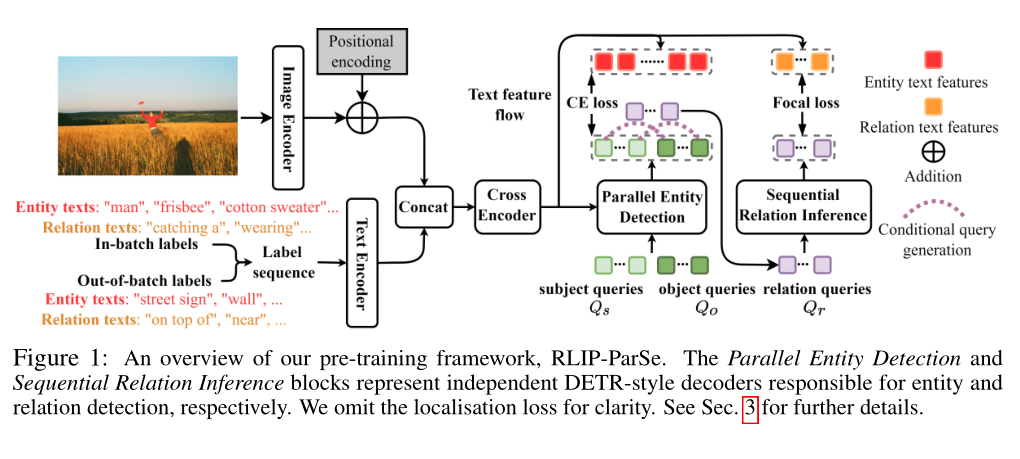
[NeurIPS 2022 Spotlight] RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Hangjie Yuan, Jianwen Jiang, Samuel Albanie, Tao Feng, Ziyuan Huang, Dong Ni and Mingqian Tang.


- RLIP is the first work to use relation texts as a language-image pre-training signal.
- RLIP-ParSe achieves SOTA results on fully-finetuned, few-shot, zero-shot HOI detetction benchmarks and learning from noisy labels.
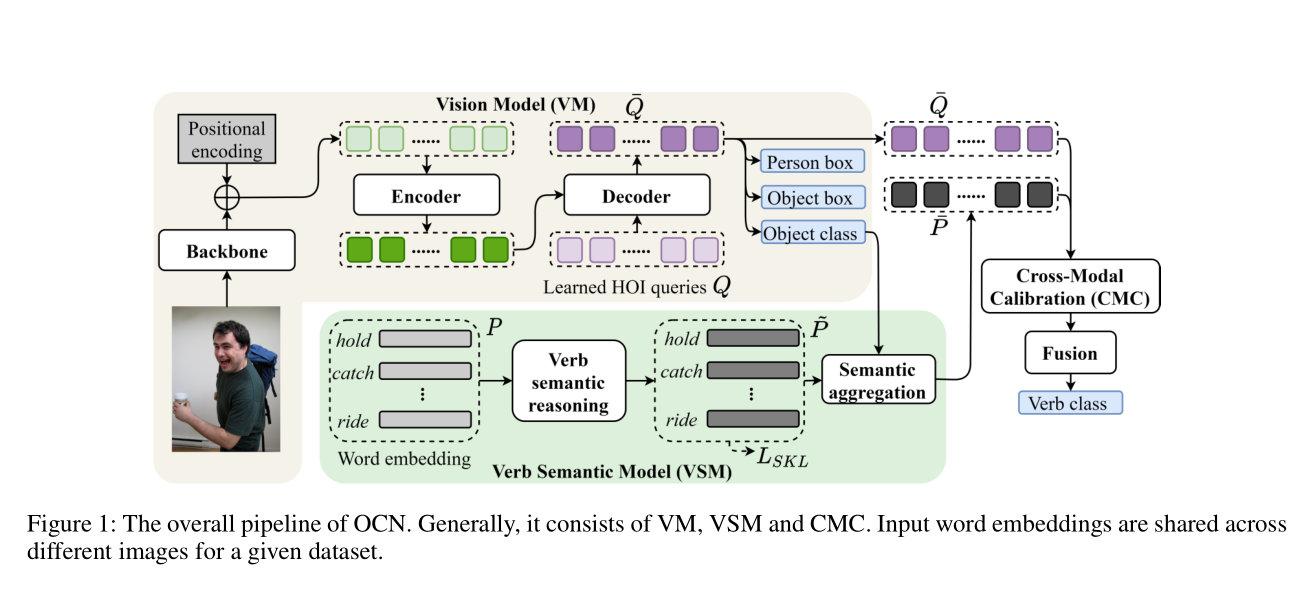
[AAAI 2022] Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics
Hangjie Yuan, Mang Wang, Dong Ni and Liangpeng Xu.


- OCN proposes a two-stage HOI detection method by decoupling entity detection and relation inference.
- OCN incorporates language and statistical prior to facilitate verb inference.
Video Understanding
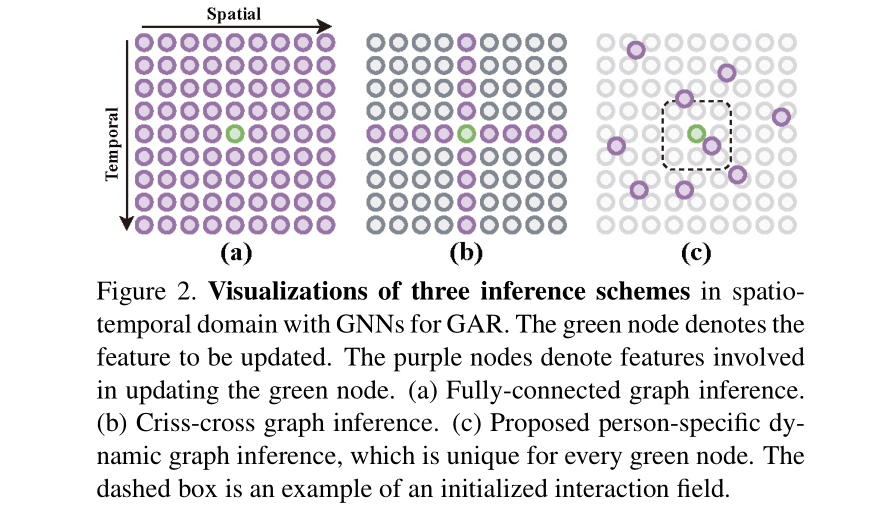
[ICCV 2021] Spatio-Temporal Dynamic Inference Network for Group Activity Recognition
Hangjie Yuan, Dong Ni and Mang Wang.


- DIN proposes to perform spatio-temporal dynamic inference.
- DIN achieves SOTA results on Volleyball and CAD benchmarks while costing much less computational overhead of the reasoning module.
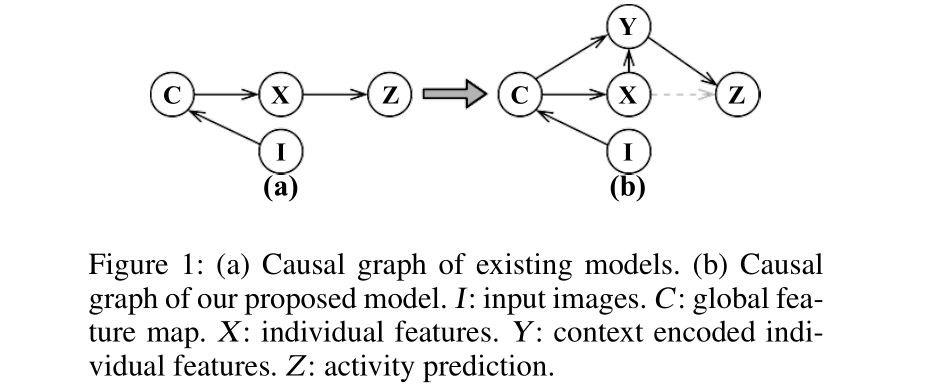
[AAAI 2021] Learning Visual Context for Group Activity Recognition
Hangjie Yuan and Dong Ni.
[video talk]
- This paper proposes to incorporate visual context when recognizing activities. This should work for other related problems as well.
- This paper achieves SOTA results on Volleyball and CAD benchmarks.
- [arXiv] Few-shot Action Recognition with Captioning Foundation Models, Xiang Wang, Shiwei Zhang, Hangjie Yuan, Yingya Zhang, Changxin Gao, Deli Zhao, Nong Sang.
AI for Science and Engineering
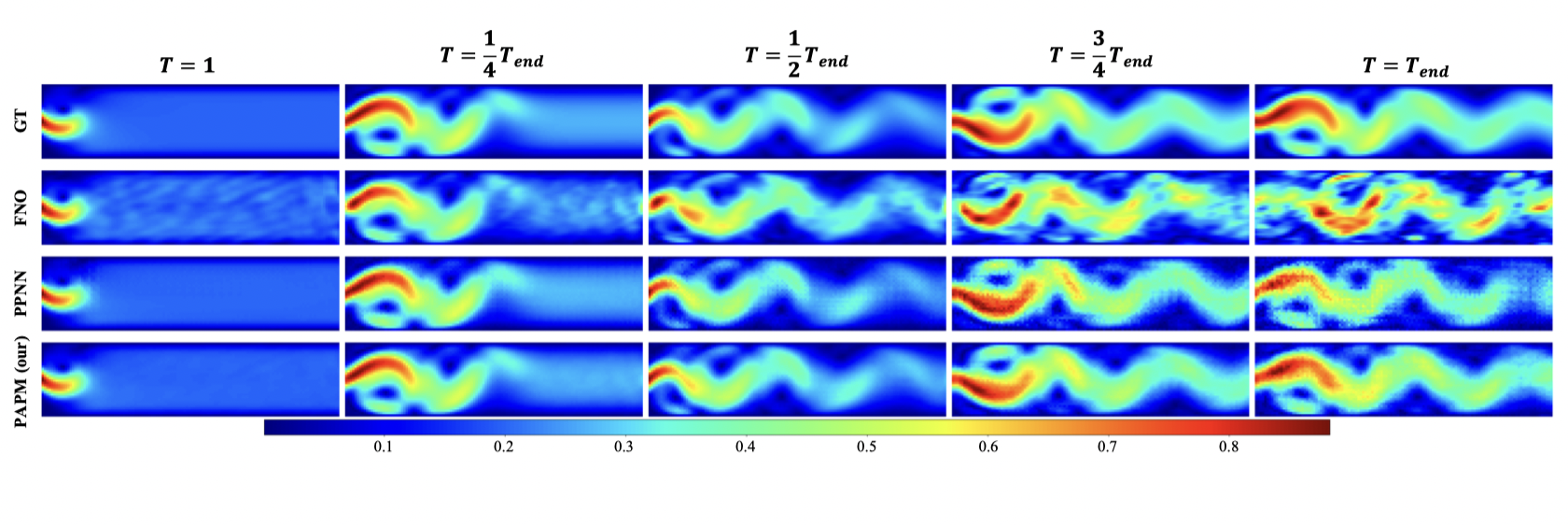
[ICML 2024] PAPM: A Physics-aware Proxy Model for Process Systems
Pengwei Liu, Zhongkai Hao, Xingyu Ren, Hangjie Yuan, Jiayang Ren, Dong Ni.
[code]
- PAPM is a pioneering work that fully incorporates partial prior physics of process systems to enable better generalization capabilities.
-
[ICLR 2024] LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition, Lingfeng Liu, Dong Ni, Hangjie Yuan. [code]
-
[WACV 2024] From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation, Ruxue Wen, Hangjie Yuan, Dong Ni, Wenbo Xiao, Yaoyao Wu. [code]
Incremental / Continual Learning
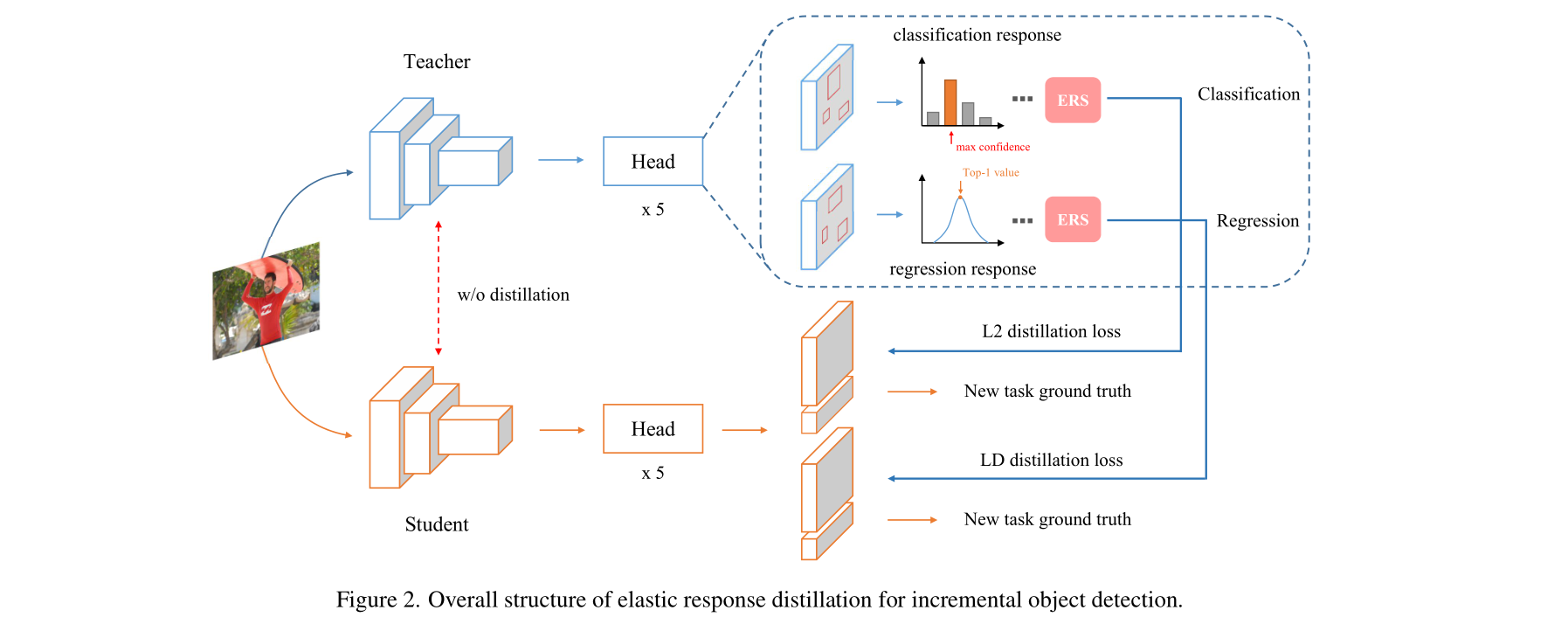
[CVPR 2022] Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation
Tao Feng, Mang Wang and Hangjie Yuan.


- This paper proposes a response-only distillation method for Incremental Object Detection, dubbed Elastic Response Distillation.
- This paper achieves SOTA results on COCO benchmarks while utilizing much fewer responses for distillation.
-
[NeurIPS 2024] Make Continual Learning Stronger via C-Flat, Ang Bian, Wei Li, Hangjie Yuan, Chengrong Yu, Zixiang Zhao, Mang Wang, Aojun Lu, Tao Feng. [code]
-
[IJCAI 2024] Revisiting Neural Networks for Continual Learning: An Architectural Perspective, Aojun Lu, Tao Feng, Hangjie Yuan, Xiaotian Song, Yanan Sun.
-
[arXiv] Progressive Learning without Forgetting, Tao Feng, Hangjie Yuan, Mang Wang, Ziyuan Huang, Ang Bian, Jianzhou Zhang.
💻 Internships
- 2021.03 - 2024.08, Alibaba Tongyi Wan Team / Alibaba DAMO Academy.
- Advisor: Deli Zhao, Shiwei Zhang, Jianwen Jiang and Mang Wang.
🎓 Academic Service
- Area Chairs & Senior Program Committee:
- ICLR 2026
- NeurIPS 2026
- Reviewing
- Conferences:
- ICLR 2024-2026
- SIGGRAPH 2024-2025
- SIGGRAPH Asia 2025
- ICML 2025-2026
- NeurIPS 2023-2026
- CVPR 2022-2026
- ICCV 2023-2025
- ACL ARR 2026
- ECCV 2024-2026
- AAAI 2023-2026
- Journals:
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- ACM Transactions on Graphics (TOG)
- IEEE Transactions on Visualization and Computer Graphics (TVCG)
- Transactions on Machine Learning Research (TMLR)
- IEEE Transactions on Multimedia (TMM)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
- Knowledge-Based Systems (KBS)
- Pattern Recognition (PR)
- Awards:
- ICML 2026 Silver Reviewer Award
- Conferences:
💬 Miscellaneous
-
Goal of my research: While conducting research, I prioritize humanity above all else. Therefore, the ultimate goal of my research is to prioritize human well-being.
- Characteristics:
-
I am friendly from a personal perspective (this is not biased!). Although I major in Computer Science Engineering, I am quite emotionally sensitive, often grasping other people’s sense of feelings faster than most people. (Some people may say this is a gift. Well, I’ll take it!) However, I am not emotionally vulnerable.
-
I describe myself as a realistic idealist. For years, I have been searching for the purpose of life and found my Goal of Research (see above). I resonate with Steve Jobs’ philosophy, saying that “The people who are crazy enough to think they can change the world are the ones who do.”.
-
-
The following list might be dynamic 😆.
-
Favoriate singer: Taylor Swift. I officially became a Swiftie after the release of “Safe & Sound”.
- Concerts that I have been to:
- Hans Zimmer Live in Hangzhou, 2025 (legendary film score composer).
- Imagine Dragons’ LOOM World Tour in Hangzhou, 2025.
- Ed Sheeran’s +-=÷× Tour in Hangzhou, 2025 (where I saw Langlang).
- Taylor Swift’s Eras Tour in London, 2024 (where I saw Ed Sheeran as well!).
- Coldplay’s Music of the Spheres World Tour in Singapore, 2024.
- One Love Asia Festival in Singapore, 2023.
-
Favoriate athlete / football club: Kylian Mbappé and Tottenham Hotspur F.C. We’re on a mission to win a trophy! And yeah, I respect the big guys like Man City, Man United, Chelsea, Arsenal… even if they are the competition.
- Favoriate movie / TV Series: Iron Man I, While You Were Sleeping (i.e., 당신이 잠든 사이에, starring Bae Suzy and Lee Jong-suk), the Harry Potter series (I am a fan of Hermione Granger), Batman (starring Christian Bale, including Batman Begins, The Dark Knight and The Dark Knight Rises), The Amazing Spider-Man I&II (starring Andrew Garfield and Emma Stone).
-
- English proficiency: I once dabbled with the TOEFL and snagged a score of 107. Not to brag, but I also clinched the Special Prize (top 0.1%) in the National English Competition for College Students. English reading and writing? Totally my jam, although there’s much room for improvement. Flashback to high school: I entertained the idea of moonlighting as a translator. Fast forward to now: English has morphed into more of a hobby as I dive deep into the world of AI research. While I’m certainly no linguistic prodigy, there’s a certain joy I find in crafting sentences in English, especially when penning down my research papers. But then GPT-4 came along and made my hobby feel, well, a tad redundant. 😅 Why? Because this section is also polished by GPT-4.
🎖 Honors and Awards
Below, I exhasutively list some of my Honors and Awards that inspire me a lot.
- 2025-09 Zhejiang Provincial Special Grant for Postdoctoral Research (Top 10 in Zhejiang Province) (浙江省博士后科研项目特别资助)
- 2025-02 Outstanding Doctoral Dissertation of Zhejiang University (Top 3 in our college)
- 2024-01 Outstanding Research Intern in Alibaba Group (Top 20 in 1000+ candidates)
- 2024-01 Outstanding Graduates of Zhejiang University
- 2023-09 International Travel Grant for Graduate Students
- 2022-02 AAAI-22 Scholarship
- 2021-10 Runner-up in ICCV 2021 Masked Face Recognition Challenge (Webface260M track) [ICCV report]
- 2020-12 Social Practice Scholarship of Zhejiang University
- 2019-05 Outstanding Graduates of Zhejiang Province
- 2017~2018 Provincial Government Scholarship for two consecutive years (Top 5%)
- 2016~2018 The First Prize Scholarship for three consecutive years (Top 3%)
- 2018-05 Honorable Mention in Mathematical Contest in Modeling
- 2017-11 Second Prize in National Mathematical Modeling Contest (Top 5%)
- 2017-01 Frist Prize in Physics Competition for College Students in Zhejiang (Top 5%)
- 2016-11 National Scholarship (Top 1% among all undergraduates)
- 2016-05 Special Prize, National English Competition for College Students (Top 0.1%)